
Database normalization (or normalisation) is the process of organizing
the columns (attributes) and tables (relations) of a relational database to
achieve these goals:
·
Eliminating redundancy
·
Ensuring data is stored in the correct
table
·
Eliminating anomalies, caused by poorly
planned, un-normalized databases.
TYPES OF ANAMOLIES:
An Insert
Anomaly occurs when certain attributes cannot be inserted into the database
without the presence of other attributes.
A Delete
Anomaly exists when certain attributes are lost because of the deletion of
other attributes.
An Update
Anomaly exists when one or more instances of duplicated data is updated,
but not all.

We have built a new Hall (e.g. B1) but it has not yet been timetabled
for any subjects. Thus insert anomaly.
Removing
Subject Code: 102 from the above table, the details of room A2 get deleted.
Thus delete anomaly.
Improving A3 to 500 will raise update anomaly
FIRST NORMAL FORM (1NF):
First normal form excludes variable repeating fields and groups. A
relation is in first normal form if the domain of each attribute contains only
atomic values, and the value of each attribute contains only a single value
from that domain.
Introduced by Sir E.F.Codd in year 1971 to counter the following
drawbacks of DBMS.
o
Eliminate repeating groups in individual
tables.
o
Create a separate table for each set of
related data.

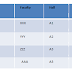
We re-arrange the relation
(table) as below, to convert it to First Normal Form.
Table
in 1NF:

Each attribute must contain only
a single value from its pre-defined domain.




No comments:
Post a Comment